- Home
De data waardeketen
Kees de Vaal2 oktober 2023Datamanagement
In het vorige artikel van deze serie bestudeerden we de verschillen en overeenkomsten tussen de jager-verzamelaar uit de begintijd van de mens en de moderne dataverzamelaar. Het artikel eindigde met vragen over de databehoefte en het inzicht dat verkregen moet worden. In dit artikel gaan we ons daar wat verder in verdiepen.
Waar komt de behoefte aan data vandaan? Het gaat niet om de data zelf, de data zijn een middel om een doel te bereiken voor een bepaalde doelgroep. Het achterliggende idee van de behoefte aan data is (of zou moeten zijn) dat er waarde mee wordt gecreëerd. Zonder doel zijn data waarde-loos!
Enkele voorbeelden van behoefte aan data verzamelen:
- data zijn een bron van informatie en worden verzameld uit intellectuele nieuwsgierigheid;
- data leiden tot inzicht in procesprestaties (voice of the process) en worden gebruikt om die prestaties op de werkvloer te tonen en het proces te monitoren en te verbeteren;
- data worden verzameld om aan te tonen dat een organisatie compliant is met wet- en regelgeving;
- data worden verzameld in een ecosysteem van samenwerkende bedrijven om inzicht te krijgen in de prestaties en knelpunten binnen de keten;
- ervaringsdata van gebruikers worden verzameld (voice of the customer) om producten en diensten te evalueren en te verbeteren;
- data worden verzameld om beslissingen te onderbouwen;
- data worden verzameld om prestaties van een organisatie in beeld te brengen en te communiceren en te verantwoorden naar stakeholders (klanten, medewerkers, maat-schappij, financiers, toezichthouders) (license-to-operate).
Het besluit om bepaalde data met een bepaald doel te gaan verzamelen vormt het begin van de data waardeketen die we hierna verder gaan onderzoeken.
Alleen wanneer duidelijk is welke data met welk doel en op welke wijze verzameld gaan worden, heeft het zin om de volgende stappen te zetten om het gewenste doel te realiseren. Het datavraagstuk dient vanuit de vraagkant te worden benaderd. Eerst bepalen welke vraag door de data beantwoord moet worden en dan op zoek gaan naar passende data. Een werkwijze die invulling geeft aan een goed-gedefinieerde behoefte en die past in de data waardeketen.
Op basis van voortschrijdend inzicht kunnen vervolgvragen op dezelfde wijze worden behandeld. Verzamelen van data uit angst dat bij het niet-verzamelen informatie verloren gaat, is een slechte motivator.
 Dit artikel is gebaseerd op de hoofdstukken 3 en 4 van het boek 'De Kwaliteit van Data' van de sectie Data & Kwaliteit van het NNK.
Dit artikel is gebaseerd op de hoofdstukken 3 en 4 van het boek 'De Kwaliteit van Data' van de sectie Data & Kwaliteit van het NNK.
In 2018 richtte Arend Oosterhoorn de sectie Data en Kwaliteit van het NNK (Nederlands Netwerk voor Kwaliteitsmanagement) op. Onze missie is het gebruik van data en de bijdrage daarvan aan het leveren van kwaliteit in een snel veranderende omgeving voortdurend aanjagen en verbeteren. Een van de doelen was het publiceren over onze bevindingen. In de loop van 2020 ontstond het idee het verzamelde materiaal in een boek te verwerken. Arend heeft hieraan een belangrijke bijdrage geleverd. Na zijn overlijden begin 2022 heeft Kees de Vaal samen met de andere leden van de sectie het boek voltooid.
Het boek De Kwaliteit van Data bevat vijf delen: Het veranderende ecosysteem, Data verzamelen en beheren, Data analyseren met statistische methoden, Data analyseren met kunstmatige intelligentie en Data presenteren en duiden.
Het boek is verkrijgbaar via de webwinkel van uitgeverij Boekscout, bol.com, managementboek.nl en de boekhandel (ISBN: 9789464683721).
In een reeks artikelen bespreken leden van de NNK-sectie Data en Kwaliteit onderwerpen uit het boek.
Lees ook: De reis naar een datagedreven wereld, en: De datawereld stelt aanvullende eisen aan de bedrijfsvoering, De jager-dataverzamelaar en Is er sprake van digitale soevereiniteit?
Beluister ook de NNK-podcast waarin hoofdstukken uit het boek 'De kwaliteit van data' worden besproken.
Data waardeketen
De data waardeketen geeft de route weer die de data gaan afleggen om uiteindelijk het verhaal van de data te vertellen (fig. 1).
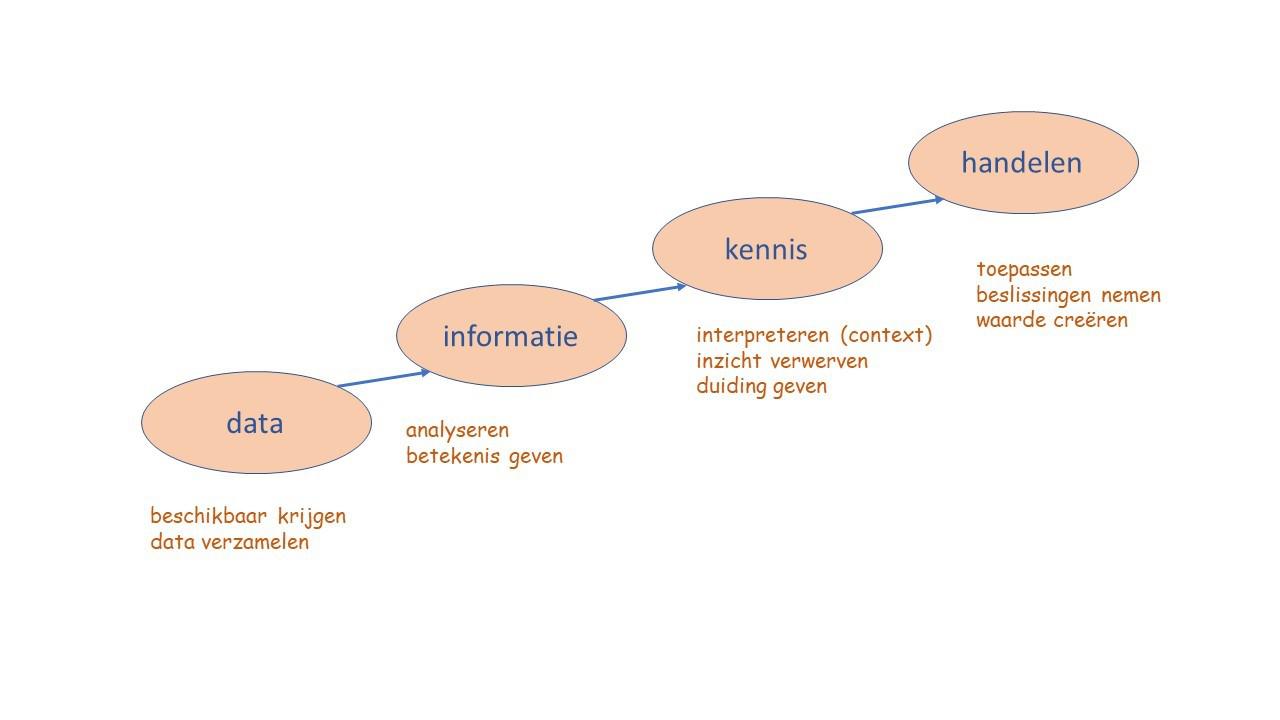
De data waardeketen begint met het beschikbaar krijgen en verzamelen van data. Data die behoren bij een vraagstelling en waarvan we hebben vastgesteld dat ze voldoen aan kwaliteitseisen. Data moeten onder meer valide en nauwkeurig zijn en geen bias vertonen, we komen daar verderop op terug.
Jacquelien Scherpen, hoogleraar meet- en regeltechniek RUG
Dan volgt de fase van het analyseren van de data en betekenis geven aan de data. Dat leidt tot informatie. Zo geeft het analyseren van procesparameters ons informatie over de mate waarin het proces binnen zijn regelgrenzen opereert en kunnen klantwaarderingsdata ons iets vertellen over de ervaringen van klanten met onze producten.
Het interpreteren van data is vaak afhankelijk van de context waarbinnen de data zijn verzameld. Interpreteren leidt tot het verwerven van inzicht en het geven van duiding aan de data. Een langetermijnanalyse van procesdata geeft een beter inzicht in de procesprestaties dan een blik op een eenmalige, kortstondige overschrijding van de regelgrenzen. Informatie over de achtergronden van ons productportfolio en welke producten wanneer zijn geïntroduceerd, helpt bij het duiding geven aan klantwaarderingsdata.
In deze fase komt het verhaal achter de data tot leven. Dat kan door het visueel presenteren van de data aan de doelgroep of door de kennis die uit de data is gehaald aan de doelgroep te vertellen in de vorm van een verhaal.
Het analyseren van data is vaak een ‘technische’ kwestie: statistische hulpmiddelen worden ingeschakeld of data scientists bouwen een algoritme waarmee de analyse ter hand wordt genomen. Bij het interpreteren van de verkregen informatie is domeinexpertise nodig. Mensen met kennis van het gebied waarover data zijn verzameld (proces, systeem, onderzoeksdomein).
Vervolgens komt de fase van handelen. Kennis wordt vertaald naar toepassen of naar het nemen van goed onderbouwde besluiten. Kennis van procesprestaties kan leiden tot procesinnovaties. Kennis over klantwaardering kan leiden tot productinnovaties. Kennis over de details van een business case kan leiden tot een verantwoorde investering. Zo voegen data waarde toe. Waarde toevoegen kan in allerlei vormen, zoals: financiële waarde (rendement), ecologische waarde (milieu), maatschappelijke waarde, intellectuele waarde (wijsheid).
In de voorbeelden is ervan uitgegaan dat elke stap een menselijke handeling vraagt: het analyseren van data, het interpreteren van data, het toepassen van de verworven kennis. Dat zal ook vaak zo zijn. Maar de ontwikkelingen gaan snel. Steeds meer organisaties zijn in hoge mate data-driven. Dat houdt ook in dat de data waardeketen geheel of grotendeels zonder menselijke interactie tot stand kan komen.
Een voorbeeld illustreert het aansturen van een fabriekslijn op basis van data. Voor een fabrikant van machines voor het maken van pizza’s is een systeem ontwikkeld dat de aangebrachte hoeveelheid kaas reguleert. Het systeem maakt foto’s van de pizzabodems op de lopende band, direct als de kaas daarop gestrooid wordt. Deze foto’s worden geanalyseerd op basis van een model en een algoritme signaleert of de hoeveelheid kaas te hoog of te laag is. Je zou dit in een dashboard aan de operator van de lopende band kunnen laten zien.
Het werkt nóg beter als een actie volautomatisch uitgevoerd wordt. Daarom stuurt het systeem automatisch een signaal naar de programmable logic controller in de machine om de aanvoer van kaas bij te stellen. De kwaliteit gaat omhoog, de kosten omlaag en er is minder personeel nodig om het proces aan te sturen. Zo worden data toegepast om direct en tastbaar waarde te leveren voor de organisatie.
Bron: Computable, 2021
De data waardeketen schetst een viertal fasen die logisch op elkaar volgen en uiteindelijk leiden tot actie op basis van data. De praktijk wijst uit dat evenwel niet na elke fase een volgende fase wordt ingezet.
Nu is dat soms ook niet nodig, denk aan het verzamelen van compliance data waarbij fase 2 (informatie) aan kan geven dat een proces compliant is en geen verdere actie nodig is. Maar ook als er wel een volgende fase gewenst is, blijft die nogal eens achterwege. Data worden dan verzameld zonder dat dat een doel dient.
Datakwaliteit
Bij het verzamelen van data gaat het om de volgende vragen te beantwoorden:
- wat wil ik weten, welke kennis wil ik vergaren?
- waarom wil ik dat weten, wat wil ik doen met de vergaarde kennis (sturen, besluiten nemen, verantwoording afleggen)?
- welke data moet ik verzamelen om die kennis te verkrijgen?
- hoe kan ik deze data verkrijgen?
- over welk interval en met welke frequentie ga ik data verzamelen?
- in welke vorm is de data aanwezig (meetwaarden, metadata, tekst, beeld)?
Als we daar de juiste antwoorden op hebben gevonden is het van belang om data met de juiste kwaliteit te verzamelen.
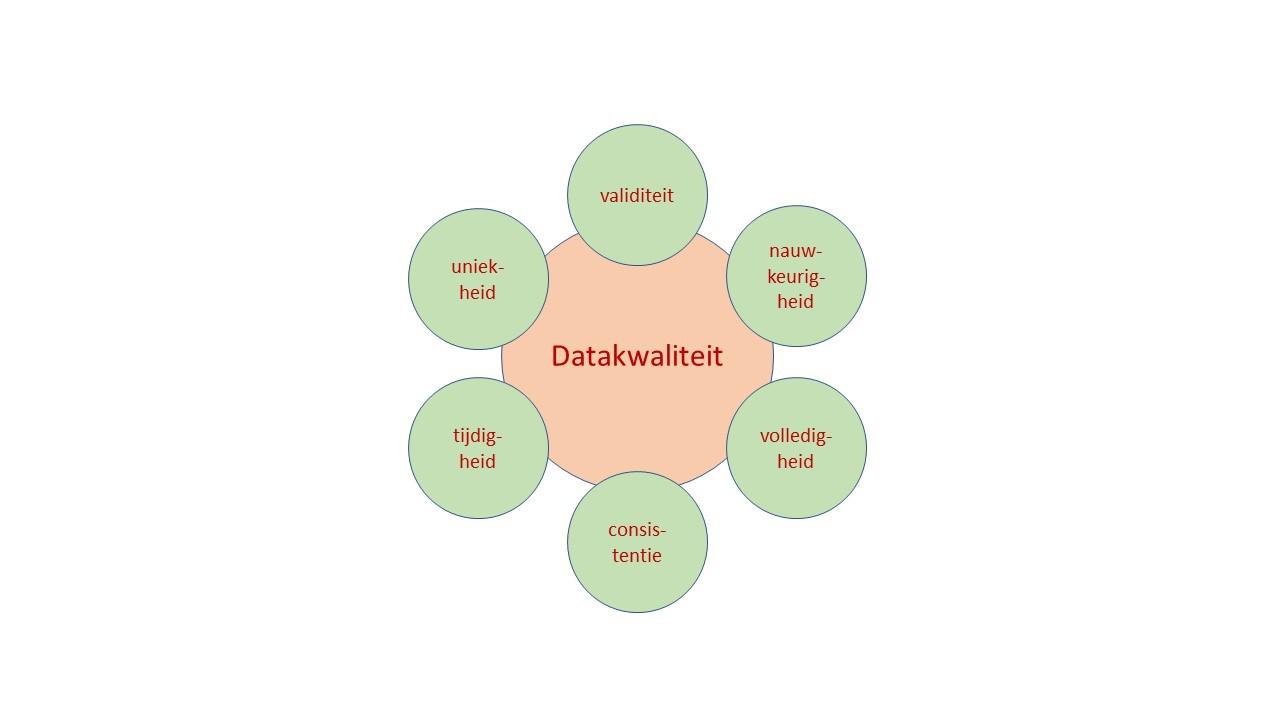
Met het begrip datakwaliteit duiden we de mate aan waarin data geschikt zijn of geschikt gemaakt kunnen worden voor het doel, zoals het nemen van een juist besluit of het stimuleren tot actie. De kwaliteit van data kan op verschillende manieren worden belicht, vaak worden de volgende zes dimensies van datakwaliteit gehanteerd (fig. 2):
- validiteit: geeft de gemeten waarde echt weer wat je feitelijk wilt weten en meten;
- nauwkeurigheid: weerspiegelt de gemeten waarde de echte (onbekende) waarde;
- volledigheid: hebben we alle data die benodigd zijn;
- consistentie: stemmen verschillende metingen van hetzelfde fenomeen voldoende overeen;
- tijdigheid: betreft het een weerspiegeling van de periode die we willen onderzoeken;
- uniekheid: zijn alle data uniek of zijn er dubbele waarden.
Mogelijke problemen
Verborgen data
Er worden enorme hoeveelheden data verzameld en dat betekent ook dat met veel data niets wordt gedaan. Ze zitten ergens in een database, gebruikers weten niet meer waar en weten überhaupt niet over welke data ze beschikken. Vaak is er sprake van een overload aan data. Het komt ook voor dat data niet meer terug te vinden zijn.
Een aparte categorie van min of meer verborgen data zijn metadata. Dat zijn eigenlijk data over data. Bijvoorbeeld bij een document kunnen de auteur, de datum van publiceren, het aantal pagina’s en de taal van het document gezien worden als metadata. Bij een telefoongesprek vormen de beller, de gebelde, het tijdstip en de duur van het gesprek metadata die een provider gedurende een bepaalde tijd kan bewaren.
Inconsistente data
Wie werkt met veel bronnen van data, kent het probleem van inconsistente data. Je importeert data uit een systeem en dan blijkt de formattering niet te kloppen met die van het systeem waarin je met de data wilt werken. Een andere bron van inconsistente data zijn bestanden waar dubbele data in voorkomen.
Ongestructureerde data
Ongestructureerde data voldoen niet aan een datamodel maar hebben hun eigen structuur. Denk aan foto’s, video’s, documenten, presentaties, e-mails, social media. Dat maakt het lastig om dit soort data te bewerken. Als we data willen analyseren en daarom van een label willen voorzien is een bepaalde structuur (datamodel) noodzakelijk. Als we bijvoorbeeld een aantal incidentmeldingen willen analyseren is het nodig daaruit de kerndata op een uniforme wijze te filteren alvorens we het analysetraject kunnen starten.
Onjuiste data
Onjuiste data zijn er in verschillende smaken. Soms zijn data op het moment van verzamelen al niet correct. Bij het invoeren van op zich juiste data kan een fout ontstaan waardoor de ingevoerde data onjuist zijn. Stel dat data afkomstig zijn van sensoren (of meetapparatuur) dan kan een foutieve instelling daarvan leiden tot onjuiste data.
Ook eens correcte data kunnen onjuiste data worden. Zo veranderen bedrijven hun naam, verhuizen mensen en bedrijven, wijzigen emailadressen en telefoonnummers, waardoor data niet meer kloppen.
'Fake' data
Onderzoekers staan vaak onder druk om artikelen te schrijven over de resultaten van hun onderzoek. Goed onderzoek vraagt veel tijd en genereert doorgaans veel data die allemaal weer verwerkt moeten worden. Wat is dan makkelijker om de data die je hebt wat uit te breiden met fake data om zo de indruk te wekken dat het een grondig onderzoek is geweest en dat de conclusies betrouwbaar zijn?
Het is natuurlijk een vorm van fraude maar wel een die steeds meer voorkomt: een recente studie toont aan dat mogelijk meer dan een kwart van de artikelen op het gebied van onderzoek naar medicijnen fake data bevat en/of geschreven is door chatbots.
Bias
Bias of vooringenomenheid is een term die gebruikt om aan te geven dat bepaalde factoren een negatieve invloed hebben op een handeling zoals uitvoeren van een meting of een onderzoek.
We kunnen bias op veel plaatsen in de data waardeketen tegenkomen. Het begint al bij het verzamelen van data.
Enkele voorbeelden: als een steekproef geen goede afspiegeling van de te onderzoeken populatie vormt, is er sprake van een selectie-bias. Als een databestand dat gebruikt wordt om een (AI)algoritme te trainen niet representatief is, treedt er een vorm van bias op waarbij het resultaat van het algoritme onbetrouwbaar is. Wie bijvoorbeeld een patroonherkenningsalgoritme traint met afbeeldingen van voornamelijk witte mannen zal merken dat het algoritme zwarte vrouwen niet of onjuist zal labelen. Bij marktonderzoeken kan een respons bias ontstaan: respondenten geven sociaal wenselijke antwoorden waardoor de onderzoeker met onjuiste data verdergaat.
Bij het analyseren en interpreteren van data kan een vorm van cognitieve bias optreden. De term is afkomstig van Daniel Kahneman (2011) en geeft aan dat we vaak geneigd zijn om door intuïtieve vooroordelen denkfouten te maken. Het algoritme dat leidde tot het Toeslagenschandaal is daar een goed voorbeeld van.
Zelfs aan het einde van de data waardeketen kan bias optreden. Het komt voor dat een onderzoeker bij het begin van zijn onderzoek al aannames heeft geformuleerd. Bij het presenteren van de resultaten ligt het dan voor de hand vooral die data te benadrukken die de aannames bevestigen: confirmation bias.
Maatregelen tegen kwaliteitsrisico’s
Er zijn wel manieren om maatregelen te treffen tegen de kwaliteitsrisico’s die hierboven geschetst zijn. Dat begint met het bewust worden van de mogelijkheid dat data inconsistent, onjuist, onvolledig kunnen zijn. Door dat verder te onderzoeken kunnen maatregelen genomen worden waardoor de kwaliteit van de data op het gewenste niveau wordt gebracht.
Bij de voorbeelden over bias is al impliciet aangegeven welke acties genomen kunnen worden om bias zo veel mogelijk te voorkomen. Verderop komen we nog een mogelijke actie tegen. Cognitieve bias bij het ontwikkelen van algoritmen kan worden aangepakt met een risk assessment waaraan zo veel mogelijk disciplines moeten deelnemen.
In de wereld van AI zijn verschillende ontwikkelingen gaande om aan de kwaliteit van een AI-systeem te werken. We noemen het FACT-model en het ontwerpen van verantwoorde AI-systemen.
FACT-model
Enkele organisaties hanteren het FACT-model als vertrekpunt om hun AI-systemen en algoritmes te toetsen (Lucic, 2020):
- Fairness: AI-systeem vermijdt bij het nemen van beslissingen of het doen van voorspellingen eni-ge vorm van discriminatie en voorkomt elke vorm van bias;
- Accountability: AI-systeem is te allen tijde betrouwbaar en het is mogelijk om vast te stellen wie aan-sprakelijk is voor een beslissing genomen door het AI-systeem;
- Confidentiality: AI-systeem is in staat persoonsgegevens zodanig te hanteren dat de privacy beschermd blijft en dat de gegevens beschermd zijn tegen onbedoeld misbruik;
- Transparancy: AI-systeem is in staat beslissingen uitlegbaar te presenteren waardoor er vertrouwen ontstaat in de voorgestelde of genomen beslissing.
Toepassen van fairness (eerlijkheid, billijkheid) kan betekenen dat de inputdata geïnspecteerd moeten worden op aanwezigheid van eventuele bias, dat het algoritme zelf getoetst wordt op zijn werking en dat de adviezen van het AI-systeem eerst door een menselijke actor worden beoordeeld alvorens deze worden geëffectueerd.
Accountability (aansprakelijkheid) betekent dat van te voren duidelijk moet zijn wie of welke organisatie aansprakelijk is voor de resultaten van het AI-systeem. Dat is niet altijd evident. Is de leverancier van een AI-platform (mede)verantwoordelijk voor de resultaten van de toepassing?
Confidentiality (vertrouwelijkheid) betekent ook voldoen aan de AVG-regelgeving en ervoor zorgen dat persoonsgegevens niet gekaapt kunnen door onbevoegden.
Transparancy (transparantie, uitlegbaarheid) is wellicht de moeilijkste van deze vier principes om toe te passen. Het recht op uitleg is verankerd is de AVG-regelgeving, maar los daarvan is de vraag of het bijvoorbeeld maatschappelijk aanvaardbaar is om AI-systemen te gebruiken die uitspraken doen die niet uitlegbaar zijn. Ook in medische sector is het strijdig met de principes van de medische ethiek om systemen te gebruiken die door hun niet-transparante resultaten mogelijk schade toebrengen aan de patiënt.
Verantwoorde AI-systemen
Zijn er mogelijkheden om verantwoorde AI-systemen te bouwen en te gebruiken? Het begint ermee dat bestuurders van organisaties moeten vastleggen wat verantwoord gebruik van AI-systemen betekent. Vervolgens is van belang dat medewerkers die AI-systemen ontwikkelen en gebruiken, getraind zijn in verantwoord gebruik van AI en zich bewust zijn van mogelijkheden en onmogelijkheden van de technologie.
Om bias in input data te voorkomen, kan een exploratory data analysis worden uitgevoerd. Onderliggende vooroordelen in gegevens komen zo naar voren en mogelijk discriminerende datasets kunnen worden gecorrigeerd. Veel aandacht moet uitgaan naar de transparantie van AI-systemen en de uitlegbaarheid van resultaten van AI-toepassingen. Ook de samenstelling van teams is van belang: voldoende diversiteit legt de basis voor creativiteit en innovatie en vergroot de sociale intelligentie van de teams.
Gedurende het ontwikkelen en gebruiken moeten risico’s voortdurend geïnventariseerd en gemonitord worden. Risicomanagers, compliance managers en auditoren kunnen hier een bijdrage leveren. Bij verantwoorde AI-systemen moet de mens en de menselijke maat centraal staan.
De gemeente Rotterdam werkt aan kwaliteitslabel voor informatieproducten. Het label geeft informatie over de totstandkoming van het product. Toekennen van het label zorgt voor transparantie en helpt om de verantwoordelijkheid voor het verstrekken van kwalitatief betrouwbare informatie op de juiste plek te leggen.
De betrouwbaarheid wordt beoordeeld aan de hand van een tiental criteria. We noemen de belangrijkste vijf:
♦ Privacy: positieve score op Privacy Risk Assessment of Data Protection Information Assessment die aangeeft dat de privacy van de burgers is gewaarborgd;
♦ Beveiliging: alleen de juiste mensen hebben toegang tot de data;
♦ Ethiek: De Ethische Data Assistent is toegepast om ethische vraagstukken tijdig te herkennen en gemaakte keuzes vast te leggen;
♦ Algoritme: een Algoritme Risk Assessment is uitgevoerd bij het gebruik van algoritmes die impact hebben op burgers of bedrijven om die impact in kaart te brengen;
♦ Datakwaliteit: score voor datakwaliteitsdashboard waarmee de gebruiker kan bepalen of de data betrouwbaar zijn.
Een kwalificatie met label A staat voor producten met een hoge impact die bij strategische besluitvorming gebruikt kunnen worden. Het product is gecontroleerd tot stand gekomen en scoort op de 10 criteria positief.
Bron: AG Connect, 2023
Een goede onderbouwing
Elke poging tot het verzamelen van data dient vooraf gegaan te worden door een goede onderbouwing van welke data voor welk doel en welke doelgroep.
Vervolgens dienen we ons bewust te zijn van mogelijke problemen die de kwaliteit van de data kunnen beïnvloeden. En gaat het erom de juiste maatregelen te treffen om de kwaliteit van de data te laten voldoen aan de eisen die gesteld worden door het beoogde doel.
Alleen dan kunnen we in het analysetraject de juiste stappen nemen om de informatie in de data te vinden en inzicht te verwerven om zo het doel van data vorm te geven.
Literatuur
- Kahneman, D. (2011). Ons feilbare denken. Amsterdam: Business Contact
- Lucic, A. (2020). Fairness, Accountability, Confidentiality, and Transparency (FACT) in AI, University of Amsterdam, presentatie, 9 April 2020.
- Stam, D., Grievink, T., Noordam, P. (2020). Succesvol datamanagement. Bergambacht: Bisnez.
- Vaal, K. de (2022). De Kwaliteit van Data. Soest: Boekscout.
Met dank aan Jan Waas voor het reviewen van dit artikel.
Auteur
 Kees de Vaal heeft zich na zijn studie Elektrotechniek aan de TU Delft gedurende bijna dertig jaar in de hightechindustrie beziggehouden met veel aspecten van kwaliteitsmanagement. Sinds 2012 is hij werkzaam als zelfstandig adviseur, principal auditor, docent en auteur. Hij was van 2000 tot 2005 voorzitter van EFQM-NL en van 2006 tot 2015 bestuurslid van NNK. Van 2013 tot 2018 was hij hoofdredacteur van het vakblad Synaps. Hij is mede-auteur van het boek Kwaliteitsmanagement in de praktijk en van het boek Perspectieven op Kwaliteit.NL.
Kees de Vaal heeft zich na zijn studie Elektrotechniek aan de TU Delft gedurende bijna dertig jaar in de hightechindustrie beziggehouden met veel aspecten van kwaliteitsmanagement. Sinds 2012 is hij werkzaam als zelfstandig adviseur, principal auditor, docent en auteur. Hij was van 2000 tot 2005 voorzitter van EFQM-NL en van 2006 tot 2015 bestuurslid van NNK. Van 2013 tot 2018 was hij hoofdredacteur van het vakblad Synaps. Hij is mede-auteur van het boek Kwaliteitsmanagement in de praktijk en van het boek Perspectieven op Kwaliteit.NL.
Dit artikel verscheen in Kwaliteit in Bedrijf, september-oktober 2023.