- Home
Op de golven van AI
Kees de Vaal30 september 2024Datamanagement
Het begrip kunstmatige intelligentie (artificial intelligence, AI) is in 1956 geïntroduceerd door John McCarthy. Het idee was om een computer zodanig te programmeren dat deze ook menselijk gedrag zou vertonen, een extraverte vorm van intelligentie. Al snel werd duidelijk dat dat – zeker met de computers van toen – niet eenvoudig zou lukken. In dit artikel bespreken we hoe AI zich in daaropvolgende decennia heeft ontwikkeld.
In de jaren '50 en '60 van de vorige eeuw doen computers hun intrede en worden ook gebruikt voor toepassingen die we nu met AI aanduiden. Zo wordt in 1955 al een programma geschreven waarmee je kon dammen. Het programma bevatte een eenvoudig, lerend algoritme. De eerste vertaalprogramma’s dateren ook uit het midden van de jaren '50. Het Amerikaanse ministerie van Defensie ondersteunde dit soort ontwikkelingen omdat tijdens de Koude Oorlog veel behoefte was aan vertalingen van Russisch naar Engels. Zelfs concepten van primitieve neurale netwerken stammen uit die periode.
De verwachtingen zijn hooggespannen. Alan Turing publiceerde al in 1950 een artikel dat begint met de vraag 'Kunnen machines denken?'. Die vraag is lastig te beantwoorden. Hij veranderde die vraag vervolgens in: 'Is het mogelijk dat een machine intelligent gedrag vertoont?'. Dat leidde tot de turingtest: een spel waarbij een ondervrager chat met een man en een vrouw. De man doet zich voor als vrouw en de vrouw moet aantonen dat de man een bedrieger is. De ondervrager moet achterhalen wie de vrouw is en wie de bedrieger. Vervolgens neemt de computer de rol van de man over. Een computer slaagt voor de turingtest als het voor de ondervrager niet gemakkelijker wordt om de bedrieger te ontmaskeren.
Eerste AI-winter
In de jaren '60 realiseren onderzoekers zich dat hun werk weinig voortgang maakt. De kwaliteit van de vertaalprogramma’s is onvoldoende en nieuwe toepassingen van AI blijven uit. Deels heeft dat te maken met onvoldoende rekenkracht van de toenmalige computers, deels met de beperkte theoretische kennis rond algoritmes. Het Lighthill rapport uit 1973, geschreven voor de British Science Research Council, vat het netjes samen en stelt dat de beloften gedaan door AI-onderzoekers nogal overdreven worden. Het leidt ertoe dat de budgetten voor de onderzoekers worden beperkt en de voortgang stagneert.
Na zo’n 20 jaar enthousiaste studies naar AI en meer of minder succesvolle toepassingen daalt de belangstelling voor AI. We spreken van de eerste AI-winter die duurt van pakweg 1974 tot 1980. Er is steeds meer twijfel of AI ooit de turingtest zal passeren.
Expert systems
In bepaalde domeinen is kennis en vooral de toepassing daarvan erg complex door een veelvoud van regels en uitzonderingen daarop. Een computer is bij uitstek geschikt om daarmee om te gaan. We spreken dan van een expert system.
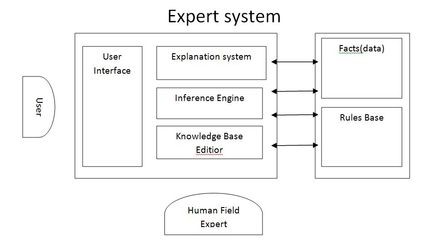
Een expertsysteem bevat een aantal componenten (figuur 1). De user interface stelt de gebruiker in staat met het systeem te communiceren.
De knowledge base editor is wellicht het belangrijkste onderdeel. De knowledge engineer die kennis heeft van het systeem maar geen domeinkennis heeft, vult hiermee de rules base en de facts. Die regels – vaak van het type ‘als… dan…’ - ontleent hij aan de expert die wel over de domeinkennis beschikt. De kennisacquisitie wordt wel gezien als de bottleneck van expertsystemen. De regels – veelal aangevuld met heuristische kennis – moeten wel algemeen geaccepteerd zijn en niet de persoonlijke opvattingen van één specifieke expert bevatten.
De inferentiemachine (inference engine) past de regels toe op de nieuwe input om output te creëren. Via het explanation system kan het systeem uitleggen hoe het tot een bepaalde output is gekomen. De inferentiemachine kan zowel voorwaarts als achterwaarts werken. Voorwaarts redeneren houdt in het toepassen van regels op inputdata. Achterwaarts redeneren start met mogelijke uitkomsten en gaat vervolgens na of via de regels voldaan is aan de benodigde voorwaarden om de conclusie geldig te laten zijn. Wanneer informatie over een voorwaarde ontbreekt kan het systeem de gebruiker om extra input vragen. Achterwaarts redeneren wordt onder meer toegepast bij medische systemen.
In de jaren' 80 zien we in toenemende mate expert systems – of beter kennisgebaseerde systemen – opkomen. De toenemende computerpower maakt het mogelijk een veelheid aan regels in te voeren en de input te verwerken tot betekenisvolle output. Daarmee vormen deze systemen de kern van de tweede AI-golf. We noemen enkele toepassingen:
- Beslissingsondersteunende systemen
De Maeslantkering is een stormvloedkering in de Nieuwe Waterweg die in 1997 in gebruik is genomen. Het is een beweegbare kering die uit twee enorme deuren (210 meter lang en 22 meter hoog) bestaat die de Nieuwe Waterweg kunnen afsluiten. Een kennisgebaseerd systeem bepaalt op basis van onder meer de huidige en verwachte waterstanden in Zuid-Holland en meteorologische data (zoals windsterkte en windrichting) of de kering gesloten moet worden.
- Adviserende systemen
Het jaarlijkse invullen van het belastingformulier is niet ieders hobby. De online versie die vrijwel iedereen gebruikt is feitelijk ook een kennisgebaseerd systeem: alle belastingregels en uitzonderingen die van toepassing zijn, zijn hierin op genomen. Het systeem loodst de gebruiker door alle rubrieken, berekent heffingskortingen en biedt de mogelijkheid om door te schuiven met aftrekposten tussen fiscale partners te komen tot een optimaal resultaat.
- Spelsystemen
In de jaren 80 zijn al enkele schaakcomputers ontwikkeld die rule-based werken. Maar pas na de tweede AI-winter wordt het serieus werd met Deep Blue van IBM die over veel meer rekenkracht beschikt. Nog weer later past Deepmind van Google een neuraal netwerk toe.
Een belangrijke eigenschap van kennisgebaseerde systemen is dat de uitkomst van berekeningen of het verstrekte advies via de regels herleidbaar is tot kennis die in het systeem aanwezig is: transparantie is inherent aanwezig.
Tweede AI-winter
Kennisgebaseerde systemen bieden goede mogelijkheden maar kennen ook beperkingen. Wanneer het aantal regels erg groot wordt zal het systeem trager worden en meer moeite hebben om nog voldoende snel uitspraken te doen. Het risico op ambigue regels is ook aanwezig, waardoor uitspraken niet volledig betrouwbaar zijn.
De acceptatie van de uitspraken speelt ook een rol. Er zijn in de jaren 70 en 80 al systemen ontwikkeld die op basis van regels artsen zouden moeten helpen met het stellen van diagnoses. Die functioneerden goed, soms zelfs beter dan de ‘gemiddelde’ arts. Maar ook toen al speelden ethische en juridische vragen. Accepteren we het advies van een computerprogramma? Wie is aansprakelijk als het programma een verkeerde diagnose stelt?
Kennisgebaseerde systemen zijn niet erg geschikt om teksten of beelden te analyseren. Het uitblijven van nieuwe doorbraken leidt ertoe dat gedurende de tweede AI-winter van ca. 1987 tot 1994 veel projecten worden stopgezet en budgetten van onderzoekers worden gelimiteerd. Opnieuw worden de verwachtingen niet gerealiseerd.
De derde golf
Na een AI-winter komt er toch weer een AI-lente. Daarvoor zijn verschillende oorzaken aan te wijzen. De belangrijkste is wel een paradigmashift. In plaats van zuivere rule-based systemen zien we machine-learning-based methodes opkomen (soms in combinatie met rule-based). Niet meer via regels een resultaat vinden, maar uit een (grote) hoeveelheid data een patroon herkennen en daarmee verder ‘redeneren’. Daarvoor moesten wel enkele randvoorwaarden worden ingevuld. De theorie rond algoritmes[1] en het trainen van machine learning systemen moest verder worden ontwikkeld, big data moest beschikbaar zijn en er moest voldoende rekenkracht (GPU’s, graphics processing units die in staat zijn parallelle bewerkingen uit te voeren) aanwezig zijn. Rond de eeuwwisseling was aan deze voorwaarden voldaan en konden nieuwe toepassingen ontwikkeld worden die vrijwel allemaal in de categorie Narrow AI vallen (zie kader).
Toen het lukte om computers te laten dammen en schaken dachten sommige wetenschappers al dat het mogelijk zou zijn dat AI elke intellectuele taak zou kunnen gaan uitvoeren die een mens ook kan. We noemen dat Artificial General Intelligence (AGI). Uiteindelijk zal de computer dan de mens op intellectueel gebied overtreffen. Men noemt dat moment ‘technologische singulariteit’, een term gemunt door Vernor Vinge en vooral gebruikt door futuroloog Ray Kurzweil[1] die dit rond 2045 ziet gebeuren. Overigens liggen dit soort voorspellingen vaak een jaar of 20 voor ons, onafhankelijk van wanneer de voorspelling is gedaan.
Vanuit allerlei disciplines is kritiek geleverd op het singulariteitsdenken. Immers intelligentie kent zoveel dimensies en is zoveel meer dan het uitvoeren van berekeningen of het toepassen van algoritmen, het gaat over het vermogen om problemen op te lossen en dat vraagt ook om inzicht in en begrip van het probleem. Belangrijker nog is dat in dit soort discussies vaak intelligentie en bewustzijn door elkaar gehaald worden (Harari[2]). Intelligentie betekent in staat zijn een probleem te begrijpen en gestructureerd naar oplossingen te zoeken en daarna het beste alternatief te kiezen. Een computersysteem volgt regels of hanteert algoritmes maar begrijpt niets en kent niet de betekenis van waar het mee bezig is. Bewustzijn is het vermogen om iets te beleven, om gevoelens, empathie en emoties te tonen en dat heeft vaak iets onvoorspelbaars. Een computersysteem kan wel emoties herkennen (affective computing), maar kent zelf geen emoties, heeft geen gevoel en programmeren daarvan lijkt een heilloze weg. Dit staat ook wel bekend als Moravec’s paradox: rekenen en algoritmes uitvoeren vraagt feitelijk weinig rekenkracht, maar waarnemen, interpreteren en handelingen verrichten (denk ook aan robots) vergt volledig andere vaardigheden. We laten deze vorm van AI graag over aan sciencefiction films en boeken.
Vanuit allerlei disciplines is kritiek geleverd op het singulariteitsdenken. Immers intelligentie kent zoveel dimensies en is zoveel meer dan het uitvoeren van berekeningen of het toepassen van algoritmen, het gaat over het vermogen om problemen op te lossen en dat vraagt ook om inzicht in en begrip van het probleem. Belangrijker nog is dat in dit soort discussies vaak intelligentie en bewustzijn door elkaar gehaald worden (Harari[2]). Intelligentie betekent in staat zijn een probleem te begrijpen en gestructureerd naar oplossingen te zoeken en daarna het beste alternatief te kiezen. Een computersysteem volgt regels of hanteert algoritmes maar begrijpt niets en kent niet de betekenis van waar het mee bezig is. Bewustzijn is het vermogen om iets te beleven, om gevoelens, empathie en emoties te tonen en dat heeft vaak iets onvoorspelbaars. Een computersysteem kan wel emoties herkennen (affective computing), maar kent zelf geen emoties, heeft geen gevoel en programmeren daarvan lijkt een heilloze weg. Dit staat ook wel bekend als Moravec’s paradox: rekenen en algoritmes uitvoeren vraagt feitelijk weinig rekenkracht, maar waarnemen, interpreteren en handelingen verrichten (denk ook aan robots) vergt volledig andere vaardigheden. We laten deze vorm van AI graag over aan sciencefiction films en boeken.
Vrijwel alle vormen van AI vallen in de categorie Narrow AI. Het gaat hierbij om systemen die één specifieke taak of soms een combinatie van een aantal taken kunnen oplossen. Narrow AI kan ons helpen om complexe problemen op te lossen en kan gezien worden als complementair aan ons brein in plaats van als vervanger van ons brein (eigenlijk zouden we deze vorm van AI dus beter Augmented Intelligence kunnen noemen).
[1] Kurzweil, R. (2006). The singularity is near. New York, NY: Penguin Putnam.
[2] Harari, Y.N. (2018). 21 lessen voor de 21ste eeuw. Amsterdam: Thomas Rap.
Machine learning (ML) is een vorm van AI waarbij een algoritme ‘leert’ doordat het steeds meer data verwerkt en daarmee de parameters in het algoritme kan aanpassen om zo steeds beter te presteren. Sinds 1980 is deze vorm van AI in opkomst en door de introductie van deep learning rond 2010 is dit verder versneld.
Er zijn drie vormen van leren in machine learning systemen:
- Supervised learning
Bij supervised learning gaat het om zorgvuldig samenstellen en vooraf juist labelen van trainingsdata. Er zijn er twee basisvarianten: classificatie en regressie.
Bij classificatie geldt dat de output een discrete waarde is. Het algoritme (bijvoorbeeld gebaseerd op Bayes) leert nieuwe data te classificeren aan de hand van de gelabelde voorbeelden. Patroonherkenning werkt volgens deze methode: leer het algoritme het onderscheid tussen hond en kat of tussen auto, bus en fiets. Ook spamfilters passen deze methode toe en LinkedIn beweert dat ze op deze manier 98% van alle nep-accounts kan verwijderen.
Bij regressie is de output een continue waarde. Dat vraagt om een ander type algoritme bijvoorbeeld gebaseerd op (lineaire) regressie. Met deze methode kunnen we bijvoorbeeld huizenprijzen schatten op basis van een aantal historische kerngegevens of weersvoorspellingen doen.
- Unsupervised learning
Bij unsupervised learning zoekt het algoritme zelf naar clusters in ongelabelde data. Het algoritme bepaalt de ‘afstand’ tussen data samples en clusters samples die minder dan een bepaalde afstand van elkaar liggen. Het kan bijvoorbeeld gaan over gebruikersgegevens van groepen mensen, zoals bij aanbevelingen door Spotify en Netflix.
- Reinforcement learning
Deze vorm van leren volgt de trial and error methode. Het algoritme krijgt achteraf feedback. Een goed resultaat leidt tot een vorm van beloning. Deze methode wordt toegepast bij het trainen van spelsystemen (Google DeepMind), maar ook in software van zelfrijdende auto’s.
Bij het trainen is van groot belang dat zowel de juiste zaken herkend worden als onjuiste zaken worden afgewezen. Dus evalueren van het ML-systeem met volledig afwijkende voorbeelden is nodig om het percentage foutpositieven te kunnen bepalen. Zo zijn er voorbeelden van ML-systemen die minuscule details (artefacten) in (satelliet)foto’s gingen uitvergroten waardoor de gepresenteerde beelden niet meer overeenkwamen met de inhoud van de foto’s. ML-systemen kunnen ook worden getraind in het herkennen van afwijkingen in producten (anomaly detection), maar dat vraagt ook weer om heel veel voorbeelden van mogelijke afwijkingen. Menselijke waarnemers zijn hier veel beter in…
Deep learning (DL) is een modelleringsmethodiek waarbij neurale netwerken centraal staan. Computers werken in essentie serieel, ze voeren berekeningen stap-voor-stap uit. Deze werkwijze is ook wel bekend als de von Neumann bottleneck. Ons brein werkt veel meer parallel. Neuronen communiceren met elkaar in een synaps, vele neuronen zijn tegelijkertijd actief en helpen ons om onze zintuigen te gebruiken, beslissingen te nemen en handelingen uit te voeren. Al in de jaren 60 werd bedacht dat neurale netwerken een oplossing zouden kunnen vormen voor problemen die eerder door parallel processing opgelost kunnen worden dan via seriële verwerking. Sinds ongeveer 2010 hebben artificiële neurale netwerken hun intrede gedaan op het terrein van deep learning. Zo’n netwerk is samengesteld uit gestapelde lagen van knooppunten die met elkaar in verbinding staan (figuur 2).

Er is altijd een invoerlaag en een uitvoerlaag. Het aantal verborgen lagen bepaalt de diepte van het netwerk. De knooppunten zijn te vergelijken met de synapsen in het menselijk brein. Door data aan te bieden aan de invoerlaag zullen de verbindingen en de knooppunten zich instellen op bepaalde waarden en daarmee een signaal genereren op de uitvoerlaag. Vaak is een van de lagen dichtbij de invoerlaag een zogenaamde convolutionele laag (Convolutional Neural Network) die in staat is typische kenmerken van de input, zoals oren van dieren, neuzen van mensen of daken van gebouwen, te herkennen en daarmee het ‘makkelijker’ maakt voor verdere lagen. De lagen dichtbij de uitvoerlaag worden meestal getraind met supervised learning. Zeer complexe deep learning netwerken kunnen miljoenen parameters bevatten die getraind zijn met terabytes aan data.
Deep learning wordt onder meer gebruikt voor spraak- en beeldherkenning. Op de invoerlaag wordt input aangeboden die op de verborgen lagen verder wordt geanalyseerd. De parameters van de verborgen lagen worden in het leertraject vaak geoptimaliseerd door het backpropagation algoritme. Hiermee zijn toepassingen als vertaalcomputers, Natural Language Processing (NLP, waaruit ChatGPT is ontwikkeld), medische diagnosesystemen, spelcomputers als Alpha Zero (ontwikkeld door Google Deepmind en in staat om in een aantal uren schaak te leren op wereldtopniveau) en zelfrijdende auto’s te realiseren.
Deep learning kan in veel gebieden worden ingezet maar kent ook beperkingen. Om een algoritme goed te trainen zijn erg veel (geschikte) data nodig. Zolang de omgeving redelijk statisch is, is dat nog te doen. Een meer dynamische omgeving eist opnieuw veel data. Zoals al eerder opgemerkt kan een algoritme correlaties in data ontdekken, maar redeneren en het leggen van oorzakelijke verbanden is toch voorbehouden aan menselijke interpretaties. Een belangrijke bron van foute conclusies komt door bias[2]. Verder beschikt een DL-systeem niet over echte inhoudelijke domeinkennis waar een menselijke waarnemer vaak al van jongs vanaf aan over beschikt. Ook komt het voor dat algoritmes iets afwijkende beelden volstrekt verkeerd interpreteren omdat deze niet voorkwamen in de training set. Nog belangrijker wellicht is het feit dat DL meestal niet transparant is, het is een black box. Hoe een beslissing in een neuraal netwerk met miljoenen parameters tot stand komt is niet na te gaan. Bij een vertaalprobleem is dat nog te billijken, maar als het gaat om het aangeven van de kans op eentumor worden fouten niet geaccepteerd. Beslissingen over mensen die niet uitlegbaar zijn, zijn in strijd met de AVG.
Een bijzondere vorm van deep learning is het Generative Adversial Network (GAN). Een GAN gaat verder dan herkenning en analyse, het genereert nieuwe informatie: beelden, teksten, muziek. Waarbij we ons moeten realiseren dat die nieuwe informatie ontstaat uit opnieuw rangschikken van bekende informatie: knip- en plakwerk. Er is geen sprake van creatie. Omdat GANs buitengewoon krachtig zijn, is het eenvoudig om iemands gezicht in een andere context te plaatsen of zelfs iemand uitspraken te laten doen die hij of zij nooit gedaan heeft of zelfs maar zou willen doen. We noemen dat deepfake. Een uitwas van AI waar al verschillende beroemdheden en politici de dupe van zijn geworden: nepnieuws is snel gegenereerd, maar wie kan deze desinformatie nog onderscheiden van echt nieuws?
Komt er een nieuwe AI-winter?
Wie de berichtgeving volgt kan snel tot de conclusie komen dat AI zo niet alle, dan toch wel veel problemen voor ons gaat oplossen. Zelfs als we ons beperken tot de Narrow AI systemen. De verwachtingen zijn hooggespannen. Dat was ook zo aan het einde van de eerste en tweede golf…
In de vorige paragraaf schetsten we al enkele fundamentele problemen rond deep learning. Die hebben ertoe geleid dat direct of indirect al heel wat projecten zijn stopgezet. Zo stopte Uber met het ontwikkelen van zelfrijdende taxi’s nadat een prototype een voetganger had overreden. Ook Apple Car is na tien jaar en tien miljard dollar investeren in februari 2024 gecancelled.
In de medische wereld zijn goede resultaten vooral op het gebied van beeldherkenning bereikt (diagnoses). Maar worden die ook toegepast in de dagelijkse praktijk? IBM heeft zijn supercomputer Watson tien jaar lang ingezet om een nieuwe toepassingen voor het stellen van diagnoses en assisteren bij behandelingen te ontwikkelingen. In 2022 is dit project gestopt: te duur, mogelijke privacy-problemen, te ingewikkeld om te voldoen aan de medische regelgeving.
Chatbots kennen een lange geschiedenis. In 1966 werd de eerste chatbot (een samenvoeging van chat en robot) gebouwd door Joseph Weizenbaum. Hij programmeerde chatbot Eliza om de oppervlakkigheid van menselijke communicatie aan te tonen maar was verrast door de gebruikers die Eliza vormen van begrip en menselijke gevoelens toedichtten. Toch deed de chatbot niet veel meer dan het klakkeloos napraten van wat de gebruiker zelf gezegd had en het uitvoeren van wat simpele scripts. De turingtest haalde Eliza niet. Voorbeelden van moderne chatbots die met ML werken zijn Siri (Apple), Assistant (Google) en Alexa (Amazon). Er zijn veel verhalen van chatbots die juist door te ‘leren’ racistische antwoorden gaven of ander ongepast ‘gedrag’ gingen vertonen en door de organisatie weer zijn uitgeschakeld. Zo kan Microsoft Bing in de war raken en dan ongepast reageren. En allerlei extensies van de chatbots van Apple c.s. zijn geen succes gebleken.
Sinds 2020 kennen we binnen het werkgebied NLP de Large Language Models (LLM), waarvan ChatGPT van OpenAI de bekendste is. De bron daarvan, GPT-4, is een neuraal netwerk (GAN) van 120 lagen met meer dan 1800 miljard parameters, getraind op terabytes aan data en werkend op een cluster van 128 GPU’s[3]. ChatGPT is in staat antwoorden te genereren op vragen (prompt in het jargon). De aanvankelijke euforie begint al weer wat te verminderen. Er zijn heel wat voorbeelden van volledig onjuiste antwoorden, racistische resultaten en problemen veroorzaakt door bias. Ook rijst de vraag of trainen op data niet strijdig is met het auteursrecht. Er lopen hierover al rechtszaken in de VS. De Europese privacy toezichthouders, waaronder de Autoriteit Persoonsgegevens, hebben OpenAI opheldering gevraagd omtrent het gebruik van persoonsgegevens bij het trainen van ChatGPT.
[1] AG Connect editie 1, 2024.
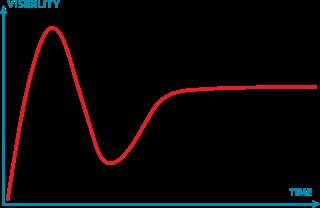
Na de piek vol opgeblazen verwachtingen zitten we nu in het dal van desillusies. Dat gebeurde ook tijdens de 2de AI-winter. Zo daalde het aantal deelnemers aan grote AI-conferenties in die periode van 5000 naar 1000.
Naderen we een 3e AI-winter[4]? Het succes van de huidige AI-toepassingen hangt voor een belangrijke deel samen met deep learning. Die techniek kent veel mogelijkheden maar ook (technische) beperkingen. Maar belangrijker is wellicht het black box karakter waardoor het uiterst moeilijk is te verklaren hoe het systeem tot zijn uitspraak komt (explainability). Een ander probleem schuilt in de training van DL-systemen. De beschikbare trainingsdata en de trainingsmethode bepalen in hoge mate de kwaliteit van het systeem.
Zo weet ChatGPT geen goede antwoorden te vinden op typisch Nederlandse vragen want getraind op Amerikaans materiaal. ChatGPT wordt wel als een ‘stochastische papegaai’ gekarakteriseerd: het genereert nieuwe teksten op basis van statistische patronen zonder zelf te begrijpen wat de tekst betekent en zonder een model te hebben van de context. En ChatGPT geeft zelf toe dat het de turingtest niet doorstaat…
Een belangrijk verschil met eerdere AI-winters is dat overheden en industrieën enorme bedragen investeren in AI-toepassingen. Dat zal ertoe leiden dat in bepaalde sectoren succesvolle toepassingen zullen worden ontwikkeld. Wij denken dat AI zeker kan helpen om bedrijfsprocessen te versnellen en te automatiseren. Dat geldt ook voor ondersteunende processen. Maar in andere sectoren kan de hype overgaan, net zoals dat geldt voor zo veel andere technologische vernieuwingen. Overheden ontwikkelen in rap tempo wetgeving (denk aan de AI Act) om grote risico’s rond AI-toepassingen te voorkomen of in ieder geval te beperken. Dat kan leiden tot meer terughoudendheid bij investeerders en ervoor zorgen dat ontwikkelingen minder onstuimig zullen verlopen dan in de afgelopen jaren het geval was[5].
Met dank aan Jan Waas voor het reviewen van een eerdere versie van dit artikel.
Auteur
 Kees de Vaal heeft zich na zijn studie Elektrotechniek aan de TU Delft gedurende bijna dertig jaar in de hightechindustrie beziggehouden met veel aspecten van kwaliteitsmanagement. Sinds 2012 is hij werkzaam als zelfstandig adviseur, principal auditor, docent en auteur. Hij was van 2000 tot 2005 voorzitter van EFQM-NL en van 2006 tot 2015 bestuurslid van NNK. Van 2013 tot 2018 was hij hoofdredacteur van het vakblad Synaps. Hij is mede-auteur van de boeken Kwaliteitsmanagement in de praktijk en Perspectieven op Kwaliteit.
Kees de Vaal heeft zich na zijn studie Elektrotechniek aan de TU Delft gedurende bijna dertig jaar in de hightechindustrie beziggehouden met veel aspecten van kwaliteitsmanagement. Sinds 2012 is hij werkzaam als zelfstandig adviseur, principal auditor, docent en auteur. Hij was van 2000 tot 2005 voorzitter van EFQM-NL en van 2006 tot 2015 bestuurslid van NNK. Van 2013 tot 2018 was hij hoofdredacteur van het vakblad Synaps. Hij is mede-auteur van de boeken Kwaliteitsmanagement in de praktijk en Perspectieven op Kwaliteit.
Noten
[1] Het begrip ‘algoritme’ heeft hiermee een meer diffuse betekenis gekregen. Oorspronkelijk betekent het een ‘recept om een probleem op te lossen’. Nu wordt het meer generiek gebruikt voor ‘een werkwijze waarmee een AI-systeem data bewerkt en omzet naar informatie’. Dat recept is eenduidig te beschrijven, die werkwijze is dat in de praktijk meestal niet.
[2] Zie Vaal, K. de. De data-waardeketen. Kwaliteit in Bedrijf, sep-okt 2023, p 22-27.
[3] Ook Bing AI van Microsoft maakt hiervan gebruik. Google Bard AI is gebaseerd op het LaMDA Language Model dat getraind is met andere data dan GPT-4.
[4] Schuchmann, S. (2019). Analyzing the Prospect of an Approaching AI Winter.
 Dit artikel is gebaseerd op hoofdstuk 9 van het recent uitgegeven boek ‘De Kwaliteit van Data’ van de sectie Data & Kwaliteit van het NNK.
Dit artikel is gebaseerd op hoofdstuk 9 van het recent uitgegeven boek ‘De Kwaliteit van Data’ van de sectie Data & Kwaliteit van het NNK.
In 2018 richtte Arend Oosterhoorn de sectie Data en Kwaliteit van het NNK (Nederlands Netwerk voor Kwaliteitsmanagement) op. Onze missie is het gebruik van data en de bijdrage daarvan aan het leveren van kwaliteit in een snel veranderende omgeving voort- durend aanjagen en verbeteren. Een van de doelen was het publiceren over onze bevindingen. In de loop van 2020 ontstond het idee het verzamelde materiaal in een boek te verwerken. Arend heeft hieraan een belangrijke bijdrage geleverd. Na zijn overlijden begin 2022 heeft Kees de Vaal samen met de andere leden van de sectie het boek voltooid.
Het boek De Kwaliteit van Data bevat vijf delen: Het veranderende ecosysteem, Data verzamelen en beheren, Data analyseren met statistische methoden, Data analyseren met kunstmatige intelligentie en Data presenteren en duiden. Het boek is verkrijgbaar via de webwinkel van uitgeverij Boekscout, bol.com, managementboek.nl en de boekhandel (ISBN: 9789464683721).
In een reeks artikelen (te vinden bij Artikelen met trefwoord Datamanagement) bespreken leden van de NNK-sectie Data en Kwaliteit onderwerpen uit het boek.